
100 - Good Guy Xorin
This problem requires a straight-forward approach:
1 for(int i=0; i<n; ++i) { 2 for(int j=0; j<m; ++j) { 3 cin>>in[i][j]; 4 for(int new_i=0; new_i<x; ++new_i) 5 for(int new_j=0; new_j<x; ++new_j) 6 ans[i*x+new_i][j*x+new_j] = in[i][j]; 7 } 8 }
250 - Model E
Solution #1
The obvious approach would be to query the whole matrix, which has a complexity of O(N2). This idea obtains a null score.
1 #!/usr/bin/python2.7 2 import sys 3 4 n = 200 5 for i in range(n): 6 for j in range(n): 7 print "%i %i" % (i, j) 8 sys.stdout.flush() 9 10 if input() == 0: 11 exit(0)
Solution #2
A better approach is to apply a binary search on each line (or column), which has a complexity of O(N * log N). This idea obtains ~40% of the maximum score.
1 #include <iostream> 2 using namespace std; 3 4 const int n = 200; 5 6 int main() { 7 for(int i=0; i<n; i++) { 8 int lo = -1; 9 int hi = n; 10 11 while(hi - lo > 1) { 12 int mid = (hi + lo) / 2; 13 14 cout<<i<<" "<<mid<<"\n"; 15 cout.flush(); 16 17 int val; 18 cin>>val; 19 20 if(val > 0) 21 hi = mid; 22 if(val < 0) 23 lo = mid; 24 if(val == 0) 25 return 0; 26 } 27 } 28 }
Solution #3
We can solve this problem in linear time (with approximately 2*n queries) by noticing that we can start from the upper right corner of the matrix and moving one step at a time to neighbouring cells, as such:
- if the value in the current cell is 0, stop execution.
- if it is bigger, go to the left.
- if it is smaller, go down.
This solution obtains 80~90% of the maximum score and can be implemented easily:
1 #!/usr/bin/python3 2 import sys 3 4 i, j = 0, 199 5 while True: 6 print("%i %i" % (i, j)) 7 sys.stdout.flush() 8 9 x = input() 10 11 if x == '0': 12 exit(0) 13 elif '-' in x: 14 i += 1 15 else: 16 j -= 1
Solution #4
The official solution uses a divide et impera approach to find the answer. Assume that the hill looks like this:
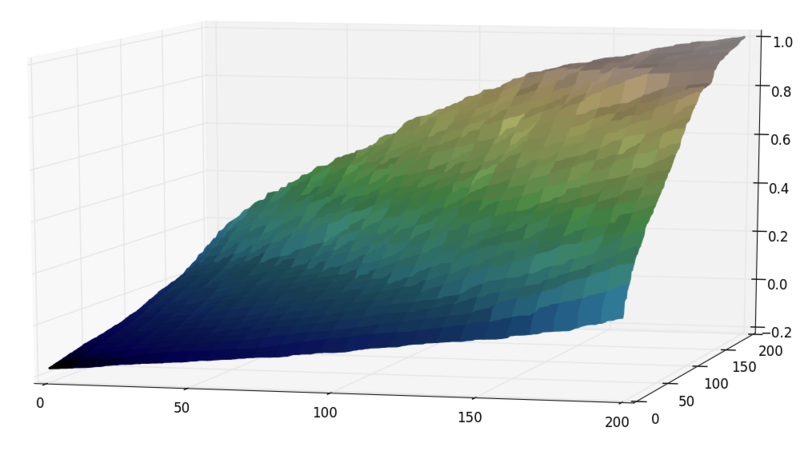
We start by taking the middle row of the matrix, and applying a binary search on that row. Once we find the element which is closest to 0, the whole matrix can be split into 4 smaller matrices, like this:
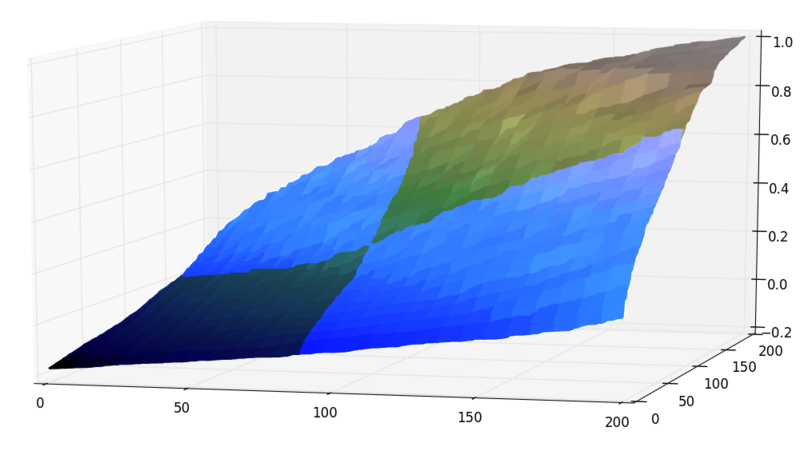
We then apply the same algorithm recursively to the highlighted parts, until we find the element 0.
This solution's complexity is more difficult to compute. In practice, it behaves better than the linear solution. Depending on the implementation, it should obtain the maximum score.
500 - 50 Shades of Prime
You need to answer the following question:
Find two integers in the interval [A, B] such that they are coprime and the distance between them is maximum.
Let's start with a brute force idea:
1 for(int i=a; i<=b; ++i) 2 for(int j=b; j>=a; --j) 3 if(gcd(i, j) == 1) 4 result = max(result, j-i+1);
Let's make a few observations:
- If one of the numbers is prime, there are a lot of valid options for the other (anything except multiples of said prime). Therefore, a starting point for the solution would be choosing the first prime in the interval together with the largest number that is not a multiple of it.
- Better pairs might still exist. However, we can infer a critical piece of information from the previous observation: the first number should be chosen from the interval [A, firstPrime]. That is, we only improve the previous solution.
- Since there are intervals that contain only one prime, towards the upper bound, we also consider the reverse: search in [A, firstPrime] and [lastPrime, B].
- To make sure that the search interval is not too large, we need to take a look at a prime gap table. For the values of A and B used in this problem, the largest prime gap does not exceed 1000.
1 long long gap = 1000; 2 for(long long i=a; i<=min(a+gap, b); ++i) 3 for(long long j=b; j>=max(a, b-gap); --j) 4 if(i <= j && gcd(i, j) == 1) 5 result = max(result, j-i+1);
1000 - Red Dragon
The solution to this problem comes with a few key observations:
- The value of the logarithm factor will never exceed log N, since all valid indices belong to the interval [1, N].
- For a fixed starting index P, the next indices (P+1, P+2, …, N) can be split into groups, each having a specific value for the logarithm factor. So, in order to maximize the value vP + vQ - floor(log2(Q - P)), one must take the maximum value among all the groups.
Based on the implementation, time and space complexity may differ. We will provide two different implementations:
Cosmin Rusu: O(N * log2 N)
This solution has the best time complexity among all the solutions and it uses the RMQ data structure.
1 #include <iostream> 2 #include <string.h> 3 #include <fstream> 4 5 using namespace std; 6 7 const int maxn = 100005; 8 const int maxlg = 18; 9 10 int rmq[maxlg][maxn * 10]; 11 12 int main() { 13 int n; 14 cin >> n; 15 memset(rmq, -0x3f3f3f3f, sizeof(rmq)); 16 for(int i = 1 ; i <= n ; ++ i) 17 cin >> rmq[0][i]; 18 19 for(int i = 1 ; i < maxlg ;++ i) 20 for(int j = 1 ; j <= n ; ++ j) { 21 rmq[i][j] = max(rmq[i - 1][j], rmq[i - 1][j + (1 << (i - 1))]); 22 } 23 24 long long ans = -0x3f3f3f3f; 25 for(int i = 1 ; i < n ; ++ i) { 26 for(int lg = 0 ; lg < maxlg ; ++ lg) { 27 int st = i + (1 << lg); 28 ans = max(ans, 1LL * rmq[0][i] + rmq[lg][st] - lg); 29 } 30 } 31 cout << ans << '\n'; 32 }
Petru Trîmbiţaş: O(N * log22 N)
Here's the simplest way to do this:
1 #include <iostream> 2 #include <set> 3 #include <cstdio> 4 #define DN 100005 5 using namespace std; 6 7 typedef pair<int,int> per; 8 int n,v[DN],rez=-(1<<30); 9 set<per, greater<per> > s[20]; 10 11 int main() { 12 //freopen("1000.in","r",stdin); 13 cin>>n; 14 for(int i=0; i<n; ++i) cin>>v[i]; 15 for(int i=1; i<n; ++i) { 16 for(int j=1,ind=1; i-j>=0; j<<=1,++ind) { 17 if(s[ind-1].find(make_pair(v[i-j],i-j))!=s[ind-1].end()) s[ind-1].erase(s[ind-1].find(make_pair(v[i-j],i-j))); 18 s[ind].insert(make_pair(v[i-j],i-j)); 19 } 20 for(int j=0; j<20; ++j) if(s[j].size()) rez=max(rez,v[i]+s[j].begin()->first-(j-1)); 21 } 22 cout<<rez; 23 }




